Adversarial-MidiBERT: Symbolic Music Understanding Model Based on Unbias Pre-training and Mask Fine-tuning
Abstract
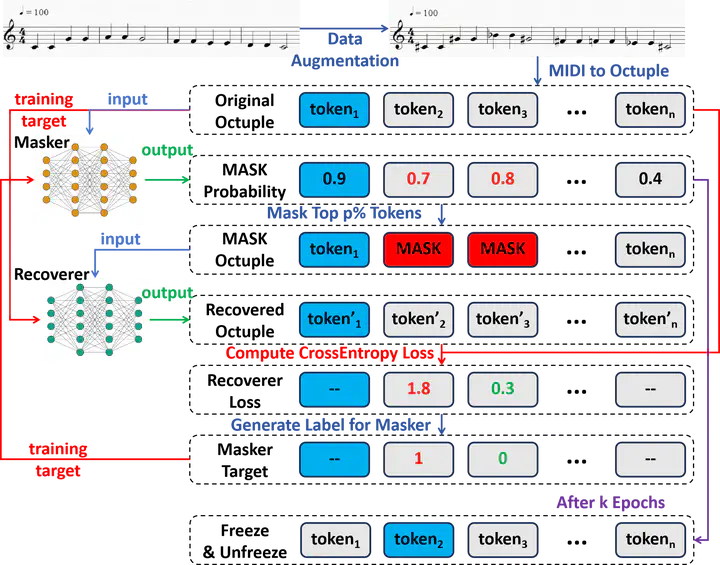
As an important part of Music Information Retrieval (MIR), Symbolic Music Understanding (SMU) has gained substantial attention, as it can assist musicians and amateurs in learning and creating music. Recently, pre-trained language models have been widely adopted in SMU because the symbolic music shares a huge similarity with natural language, and the pre-trained manner also helps make full use of limited music data. However, the issue of bias, such as sexism, ageism, and racism, has been observed in pre-trained language models, which is attributed to the imbalanced distribution of training data. It also has a significant influence on the performance of downstream tasks, which also happens in SMU. To address this challenge, we propose Adversarial-MidiBERT, a symbolic music understanding model based on Bidirectional Encoder Representations from Transformers (BERT). We introduce an unbiased pre-training method based on adversarial learning to minimize the participation of tokens that lead to biases during training. Furthermore, we propose a mask fine-tuning method to narrow the data gap between pre-training and fine-tuning, which can help the model converge faster and perform better. We evaluate our method on four music understanding tasks, and our approach demonstrates excellent performance in all of them. The code for our model is publicly available at https://github.com/RS2002/Adversarial-MidiBERT.